Despite recent advances in sparse novel view synthesis (NVS) applied to object-centric scenes, scene-level NVS remains a challenge. A central issue is the lack of available clean multi-view training data, beyond manually curated datasets with limited diversity, camera variation, or licensing issues. On the other hand, an abundance of diverse and permissively-licensed data exists in the wild, consisting of scenes with varying appearances (illuminations, transient occlusions, etc.) from sources such as tourist photos. To this end, we present WildCAT3D, a framework for generating novel views of scenes learned from diverse 2D scene image data captured in the wild. We unlock training on these data sources by explicitly modeling global appearance conditions in images, extending the state-of-the-art multi-view diffusion paradigm to learn from scene views of varying appearances. Our trained model generalizes to new scenes at inference time, enabling the generation of multiple consistent novel views. WildCAT3D provides state-of-the-art results on single-view NVS in object- and scene-level settings, while training on strictly fewer data sources than prior methods. Additionally, it enables novel applications by providing global appearance control during generation.
Our key insight is that inconsistent data can be leveraged during multi-view diffusion training to learn consistent generation, by specifically decoupling content and appearance when denoising novel views. Starting from a multi-view diffusion framework, we propose to explicitly integrate a feed-forward, generalizeable appearance encoder that models appearance variations between scene views. We add an appearance encoding branch to produce low-dimensional appearance embeddings used as conditioning signals for the multi-view diffusion model. Additionally, we employ a warp conditioning mechanism to resolve the scale ambiguity inherent to single-view NVS.
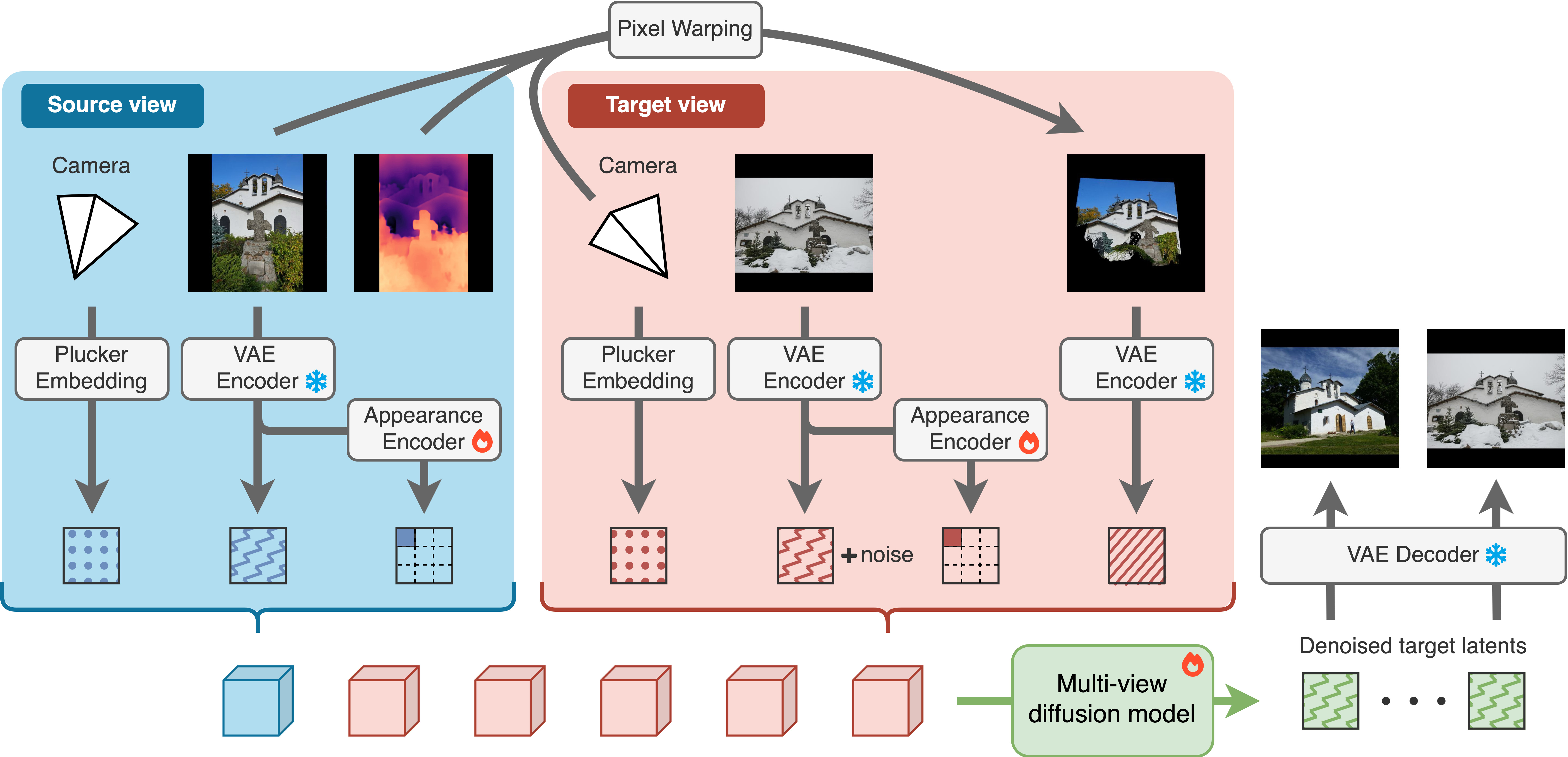
WildCAT3D significantly outperforms the previous SOTA MegaScenes NVS model (MS NVS) at generating consistent and high-quality novel view sequences from single images. Our method achieves superior performance while training on unfiltered data in-the-wild, unlike the aggressive filtering used by prior methods.



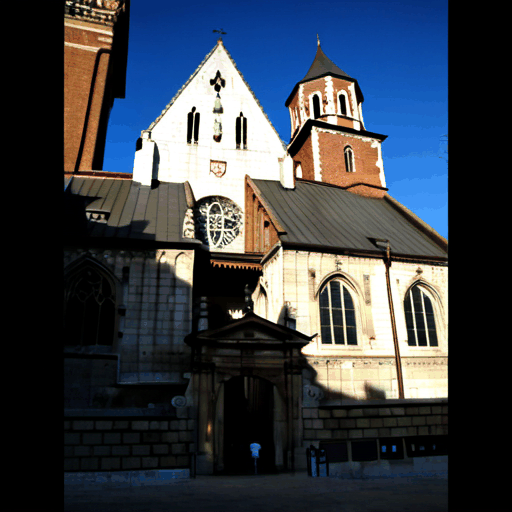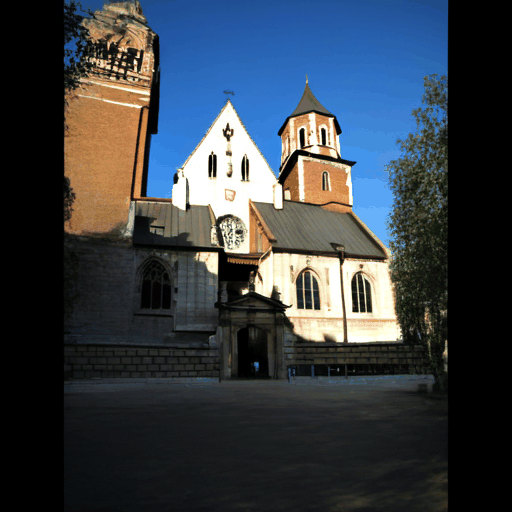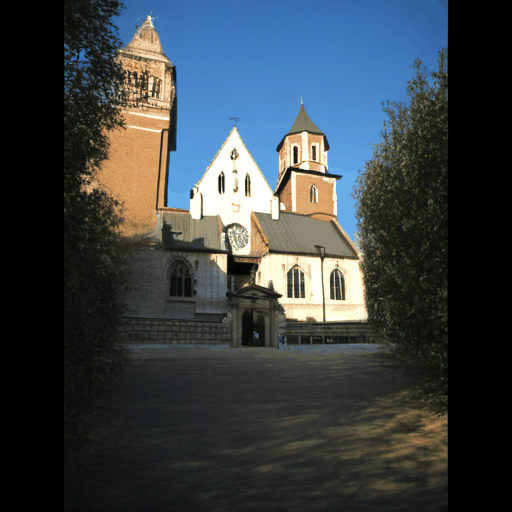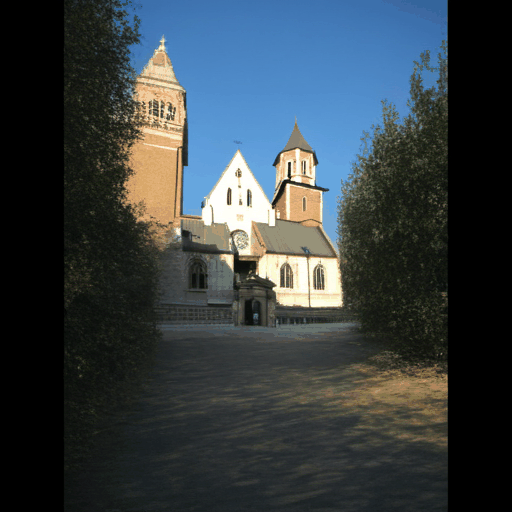
Our explicit modeling of appearance enables novel applications such as appearance-controlled generation using external conditioning images and interpolation between views of differing appearances.

Input View

Appearance Condition
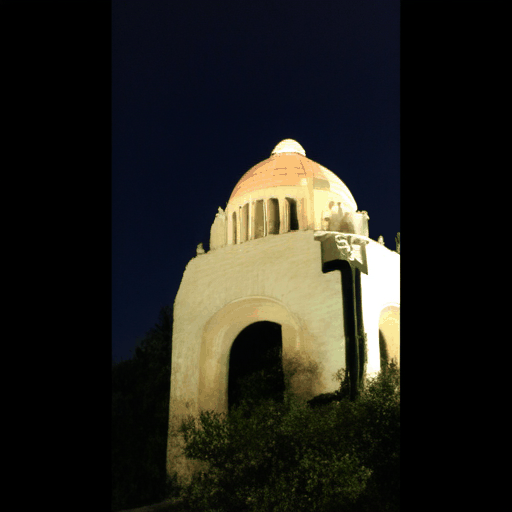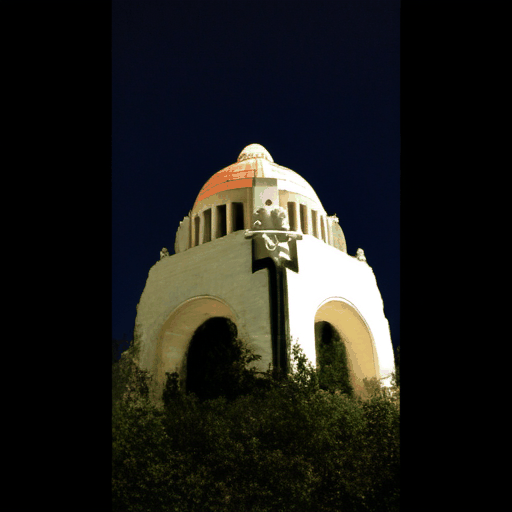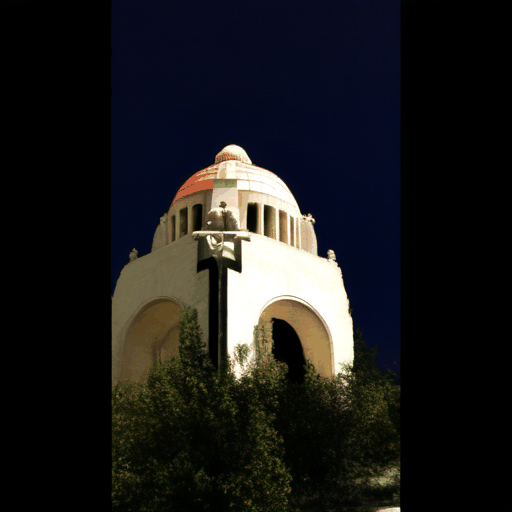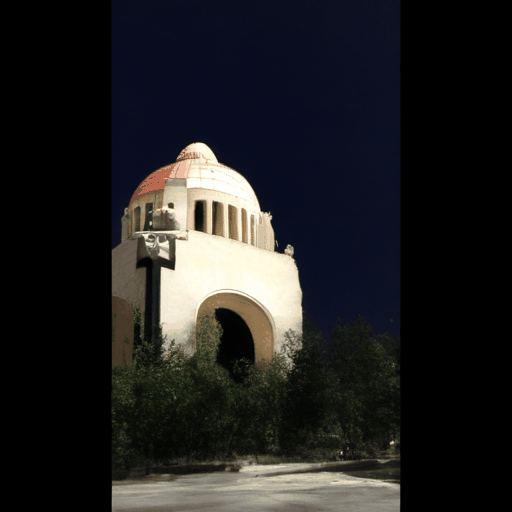
Generated Novel Views

Start View

Generated Interpolation Sequence

End View
Click here for additional results.
@InProceedings{alper2025wildcat3d,
title={WildCAT3D: Appearance-Aware Multi-View Diffusion in the Wild},
author={Alper, Morris and Novotny, David and Kokkinos, Filippos and Averbuch-Elor, Hadar and Monnier, Tom},
booktitle={Proceedings of Advances in Neural Information Processing Systems (NeurIPS)},
year={2025}
}This work was sponsored by Meta AI. We thank Kush Jain and Keren Ganon for providing helpful feedback.


